들어가며
PDF는 기업과 기관에서 가장 널리 사용되는 문서 형식 중 하나입니다. 계약서, 보고서, 논문, 매뉴얼 등 수많은 정보가 PDF로 저장되어 있습니다. 하지만 PDF에서 구조화된 데이터를 추출하는 것은 여전히 어려운 과제입니다. 텍스트 순서가 뒤섞이고, 표가 깨지며, 이미지와 차트는 해석할 수 없는 경우가 많습니다.
특히 RAG(Retrieval-Augmented Generation) 시스템을 구축할 때, PDF 문서를 얼마나 정확하게 파싱하느냐가 전체 시스템의 품질을 결정합니다. 잘못 파싱된 문서는 검색 품질 저하로 이어지고, 결국 LLM이 생성하는 답변의 정확도에 영향을 미칩니다.
OpenDataLoader PDF는 이러한 문제를 해결하기 위해 탄생한 오픈소스 PDF 파서입니다. 벤치마크 1위(0.90) 의 정확도를 자랑하며, RAG 파이프라인에 최적화된 출력을 제공합니다. 더욱이 PDF 접근성 자동화(Accessibility Automation)라는 독창적인 기능까지 갖추고 있습니다.
OpenDataLoader PDF란?
OpenDataLoader PDF는 “AI-ready data” 추출을 목표로 하는 오픈소스 PDF 파서입니다. Apache 2.0 라이선스로 배포되며, Python, Node.js, Java SDK를 모두 지원합니다.
핵심 특징
1. 높은 정확도의 데이터 추출
200개 이상의 실제 PDF 문서(다중 컬럼, 학술 논문 포함)로 구성된 벤치마크에서 종합 1위를 차지했습니다. 읽기 순서(Reading Order) 0.94, 테이블 정확도 0.93, 전체 0.90의 점수를 기록했습니다.
2. 다양한 출력 포맷
Markdown, JSON(바운딩 박스 포함), HTML, Annotated PDF, Plain Text를 지원합니다. 특히 JSON 출력은 각 요소의 좌표(bounding box)와 시맨틱 타입을 포함하여 RAG 시스템에서 출처 인용(Source Citation)에 활용할 수 있습니다.
3. 로컬 실행 가능
모든 처리가 로컬에서 이루어집니다. API 호출이나 데이터 전송이 없어 법률, 의료, 금융 문서와 같이 민감한 데이터도 안전하게 처리할 수 있습니다. GPU도 필요 없습니다.
4. Hybrid 모드
단순한 페이지는 로컬 Java 엔진으로 빠르게 처리(0.05초/페이지)하고, 복잡한 페이지는 AI 백엔드로 라우팅하여 정확도를 높이는 하이브리드 방식을 지원합니다.
 Annotated PDF 출력 - 각 요소(헤딩, 문단, 테이블, 이미지)가 바운딩 박스와 시맨틱 타입으로 감지됨
Annotated PDF 출력 - 각 요소(헤딩, 문단, 테이블, 이미지)가 바운딩 박스와 시맨틱 타입으로 감지됨
벤치마크 성능 비교
OpenDataLoader PDF는 다른 주요 PDF 파서들과 비교했을 때 뚜렷한 우위를 보입니다.
| 엔진 | 전체 | 읽기 순서 | 테이블 | 헤딩 | 속도(초/페이지) |
|---|---|---|---|---|---|
| OpenDataLoader [hybrid] | 0.90 | 0.94 | 0.93 | 0.83 | 0.43 |
| OpenDataLoader | 0.72 | 0.91 | 0.49 | 0.76 | 0.05 |
| Docling | 0.86 | 0.90 | 0.89 | 0.80 | 0.73 |
| Marker | 0.83 | 0.89 | 0.81 | 0.80 | 53.93 |
| MinerU | 0.82 | 0.86 | 0.87 | 0.74 | 5.96 |
| PyMuPDF4LLM | 0.57 | 0.89 | 0.40 | 0.41 | 0.09 |
| MarkItDown | 0.29 | 0.88 | 0.00 | 0.00 | 0.04 |
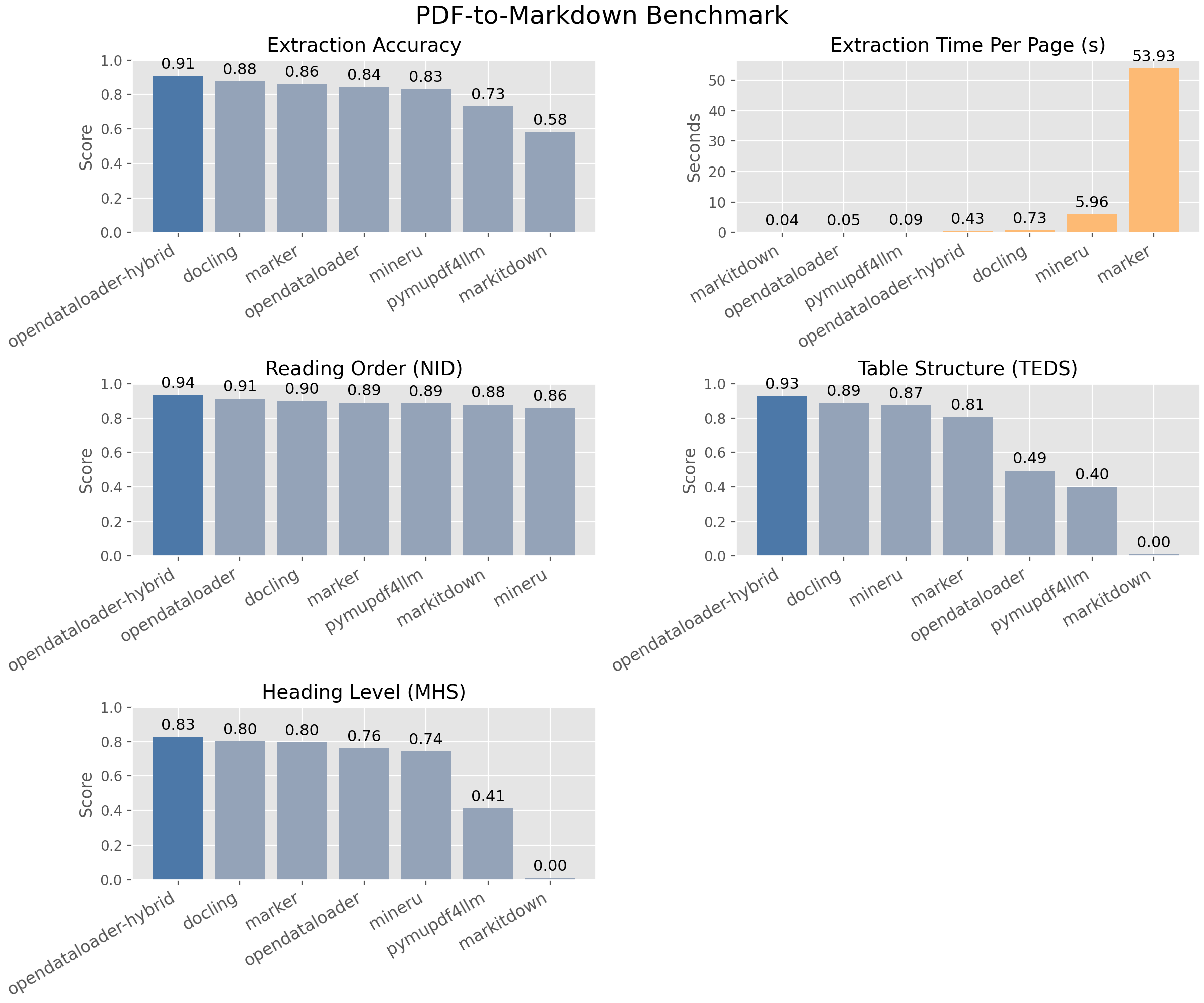
Hybrid 모드에서는 전체 정확도 0.90으로 1위를 차지했습니다. 특히 테이블 추출 정확도(0.93)가 돋보입니다. 순수 로컬 모드에서도 0.05초/페이지라는 매우 빠른 속도를 보여줍니다.
주요 기능 상세
1. 테이블 추출
단순한 테두리가 있는 테이블뿐만 아니라, 복잡한 테이블과 테두리가 없는 테이블도 추출할 수 있습니다. Hybrid 모드를 사용하면 테이블 정확도가 0.49에서 0.93으로 약 90% 향상됩니다.
import opendataloader_pdf
opendataloader_pdf.convert(
input_path=["report.pdf"],
output_dir="output/",
format="json",
hybrid="docling-fast" # 복잡한 테이블용
)
2. OCR (광학 문자 인식)
스캔된 PDF나 이미지 기반 PDF도 처리할 수 있습니다. 80개 이상의 언어를 지원하며, 300 DPI 이상의 품질에서 좋은 결과를 보여줍니다.
# 서버 시작 (OCR 활성화)
opendataloader-pdf-hybrid --port 5002 --force-ocr
# 한국어 + 영어 문서 처리
opendataloader-pdf-hybrid --port 5002 --force-ocr --ocr-lang "ko,en"
3. 수식 추출 (LaTeX)
학술 논문이나 기술 문서에서 수학 공식을 LaTeX 형태로 추출할 수 있습니다.
# 서버: 수식 추출 활성화
opendataloader-pdf-hybrid --enrich-formula
# 클라이언트
opendataloader-pdf --hybrid docling-fast --hybrid-mode full paper.pdf
JSON 출력 예시:
{
"type": "formula",
"page number": 1,
"bounding box": [226.2, 144.7, 377.1, 168.7],
"content": "\\frac{f(x+h) - f(x)}{h}"
}
4. 차트 및 이미지 설명
AI를 활용해 차트와 이미지에 대한 설명을 자동 생성합니다. RAG 검색과 접근성 alt 텍스트에 유용합니다.
{
"type": "picture",
"page number": 1,
"bounding box": [72.0, 400.0, 540.0, 650.0],
"description": "A bar chart showing waste generation by region from 2016 to 2030..."
}
5. AI 안전 기능
PDF에 숨겨진 프롬프트 인젝션 공격을 자동으로 필터링합니다. 투명 텍스트, 0크기 폰트, 페이지 외부 콘텐츠, 의심스러운 보이지 않는 레이어 등을 감지합니다.
6. Tagged PDF 지원
구조 태그가 있는 PDF에서는 작성자가 의도한 정확한 레이아웃을 추출합니다. 추측이나 휴리스틱 없이 헤딩, 리스트, 테이블, 읽기 순서가 보존됩니다.
RAG 파이프라인에서의 활용
OpenDataLoader PDF는 RAG 시스템 구축에 최적화되어 있습니다.
문서 청킹
Markdown 출력은 헤딩, 테이블, 리스트 구조가 보존되어 시맨틱 청킹에 이상적입니다. JSON 출력의 type, heading level, page number 필드를 활용해 섹션별 또는 페이지별 분할이 가능합니다.
출처 인용 (Source Citation)
JSON의 모든 요소는 bounding box([left, bottom, right, top])와 page number를 포함합니다. RAG가 답변을 생성할 때, 소스 청크를 원본 PDF의 정확한 위치로 매핑할 수 있습니다. “클릭하여 소스 보기” UX가 가능해집니다.
LangChain 통합
공식 LangChain 문서 로더가 제공됩니다.
from langchain_opendataloader_pdf import OpenDataLoaderPDFLoader
loader = OpenDataLoaderPDFLoader(
file_path=["file1.pdf", "file2.pdf"],
format="text"
)
documents = loader.load()
PDF 접근성 자동화 (Accessibility Automation)
OpenDataLoader PDF의 가장 독특한 기능은 PDF 접근성 자동화입니다.
문제 상황
전 세계적으로 접근성 규제가 강화되고 있습니다. 유럽 접근성 법(EAA)은 2025년 6월 28일부터 시행되며, ADA와 Section 508도 이미 효력을 발휘하고 있습니다. 한국에서도 디지털 포용법이 시행 중입니다.
하지만 기존 PDF의 수동 교정(Remediation)은 문서당 $50-200의 비용이 들며, 대규모로 확장할 수 없습니다.
OpenDataLoader의 접근법
PDF Association 및 Dual Lab(veraPDF 개발사)과 협력하여 자동 태깅 기능을 개발하고 있습니다. Well-Tagged PDF 명세를 따르며, veraPDF로 프로그래밍 방식으로 검증합니다.
| 단계 | 기능 | 상태 | 라이선스 |
|---|---|---|---|
| 1. 감사 | 기존 PDF 태그 확인 | 출시됨 | 무료 |
| 2. 자동 태깅 → Tagged PDF | 구조 태그 생성 | 2026 Q2 | 무료 (Apache 2.0) |
| 3. PDF/UA 내보내기 | PDF/UA-1 또는 PDF/UA-2 변환 | 엔터프라이즈 | 유료 |
| 4. 시각 편집 | 접근성 스튜디오 | 엔터프라이즈 | 유료 |
핵심은 자동 태깅부터 Tagged PDF 생성까지 완전한 오픈소스(Apache 2.0)로 제공된다는 점입니다. 기존 도구들은 대부분 태그 작성 단계에서 독점 SDK에 의존합니다.
빠른 시작
설치
pip install -U opendataloader-pdf
Hybrid 모드가 필요한 경우:
pip install -U "opendataloader-pdf[hybrid]"
기본 사용법
import opendataloader_pdf
# 모든 파일을 한 번에 배치 처리
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)
Hybrid 모드
# 터미널 1: 백엔드 서버 시작
opendataloader-pdf-hybrid --port 5002
# 터미널 2: PDF 처리
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/
Node.js
import { convert } from '@opendataloader/pdf';
await convert(['file1.pdf', 'file2.pdf'], {
outputDir: 'output/',
format: 'markdown,json'
});
Java
<dependency>
<groupId>org.opendataloader</groupId>
<artifactId>opendataloader-pdf-core</artifactId>
</dependency>
어떤 모드를 사용해야 할까?
| 문서 유형 | 모드 | 설치 명령어 |
|---|---|---|
| 일반 디지털 PDF | Fast (기본) | pip install opendataloader-pdf |
| 복잡하거나 중첩된 테이블 | Hybrid | pip install "opendataloader-pdf[hybrid]" |
| 스캔/이미지 기반 PDF | Hybrid + OCR | pip install "opendataloader-pdf[hybrid]" |
| 비영어권 스캔 PDF | Hybrid + OCR | pip install "opendataloader-pdf[hybrid]" + --ocr-lang "ko,en" |
| 수학 공식 | Hybrid + formula | pip install "opendataloader-pdf[hybrid]" + --enrich-formula |
| 차트 설명 필요 | Hybrid + picture | pip install "opendataloader-pdf[hybrid]" + --enrich-picture-description |
로드맵
| 기능 | 일정 | 라이선스 |
|---|---|---|
| 자동 태깅 → Tagged PDF | 2026 Q2 | 무료 |
| Hancom Data Loader 통합 | 2026 Q2-Q3 | 무료 |
| 구조 검증 | 2026 Q2 | 계획 중 |
Hancom Data Loader 통합은 엔터프라이즈급 AI 문서 분석 기능을 제공합니다. 고객 맞춤형 모델, VLM 기반 차트/이미지 이해, 복잡한 테이블 추출, 프로덕션급 OCR, 그리고 HWP/HWPX 네이티브 지원이 포함됩니다.
마치며
OpenDataLoader PDF는 RAG 시대에 필요한 PDF 파싱의 새로운 표준을 제시합니다. 높은 정확도, 다양한 출력 포맷, 로컬 실행, 그리고 PDF 접근성 자동화까지 하나의 도구에서 모두 해결할 수 있습니다.
특히 주목할 점은:
- 벤치마크 1위 의 객관적으로 검증된 성능
- 완전한 로컬 실행 으로 데이터 프라이버시 보장
- 바운딩 박스 를 통한 정확한 출처 인용
- Apache 2.0 라이선스 로 상업적 사용 자유로움
- 최초의 오픈소스 PDF 자동 태깅 (2026 Q2 예정)
RAG 파이프라인을 구축 중이거나, PDF 문서 처리가 필요한 프로젝트를 진행 중이라면 OpenDataLoader PDF를 한번 사용해 보시길 권합니다.
참고 자료